-
 Philip Maas authoredPhilip Maas authored
Philip Maas authoredPhilip Maas authored
Bipedal Walker Evo
This project tries to solve OpenAI's bipedal walker using three different ways: Q-Learning, Mutation of Actions and Evolution Strategies.
Q-Learning
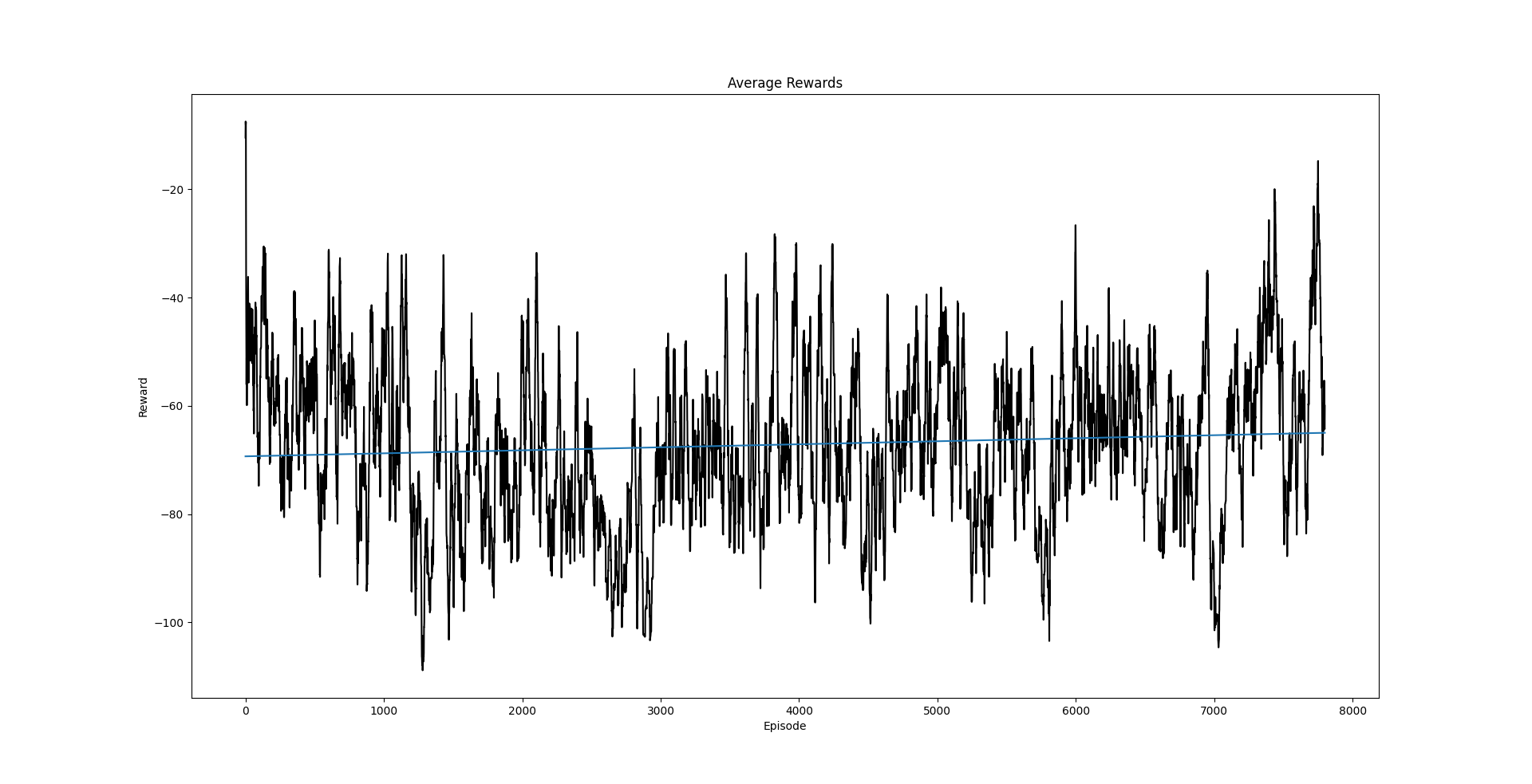
At least the walker learns to fall slower of time.
How it works
- Choose action based on Q-Function
- Execute chosen action or explore
- Save state, action, reward, next state to memory
- Create batch with random memories
- Update Q-Function
Hyperparameters
| Parameter | Description | Interval | Our Choice |
|---|---|---|---|
activation funtion |
Activation function of input and hidden layers. | ReLU | |
gamma |
Importance of future rewards. | [0;1] | 0.99 |
alpha |
Learning rate of Q-Function. | [0;1] | 0.1 |
epsilon_init |
Percentage of random actions for exploration at the start. | [0;1] | 1 |
epsilon_low |
Percentage of random actions for exploration at the end. | [0;1] | 0.05 |
epsilon_decrease |
Decrease of exploration rate per epoch. | [0;1] | 0.999 |
bins |
Discretization bins of action space. | [0;∞[ | 7 |
episodes |
Episodes per epoch. | [0;∞[ | 1 |
epochs_max |
Maximum amount of epochs. | [0;∞[ | 10,000 |
batchsize |
Batchsize for learning. | [0;∞[ | 16 |
memorysize |
Size of the memory. It's a ring buffer. | [0;∞[ | 25,000 |
network architecture |
Architecture of hidden layers. | [0;∞[² | [24, 24] |
optimizer |
Optimizer of the neural net. | Adam | |
learning rate |
Learning rate of the neural net. | [0;1] | 0.001 |
loss |
Loss function of the neural net. | mse |
Action Mutation
How it works
- Generate a population with a starting number randomized actions (we don't need enough actions to solve the problem right now)
- Let the population play the game reward every walker of the generation accordingly
- The best walker survives without mutating
- The better the reward the higher the chance to pass actions to next generation. Each child has a single parent, no crossover.
- Mutate all children and increment their number of actions
Hyperparameters
| Parameter | Description | Interval | Our Choice |
|---|---|---|---|
POP_SIZE |
Size of population. | [0;∞[ | 50 |
MUTATION_FACTOR |
Percentage of actions that will be mutated for each walker. | [0;1] | 0.2 |
BRAIN_SIZE |
Number of actions in the first generation. | [0;1600] | 50 |
INCREASE BY |
Incrementation of steps for each episode. | [0;∞[ | 5 |
Evolution Strategies
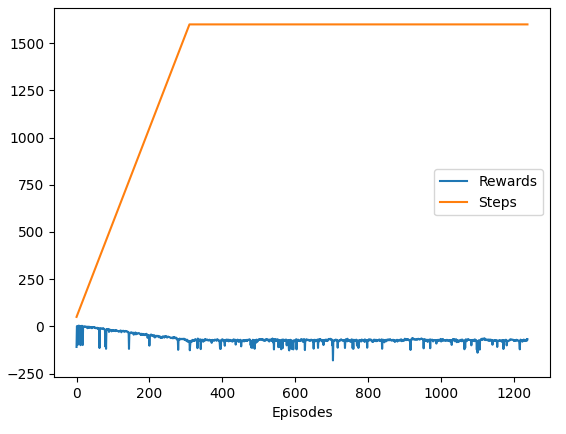
After 1000 episodes, which is about 1h of learning, it will reach ~250 reward.
Learning curve:

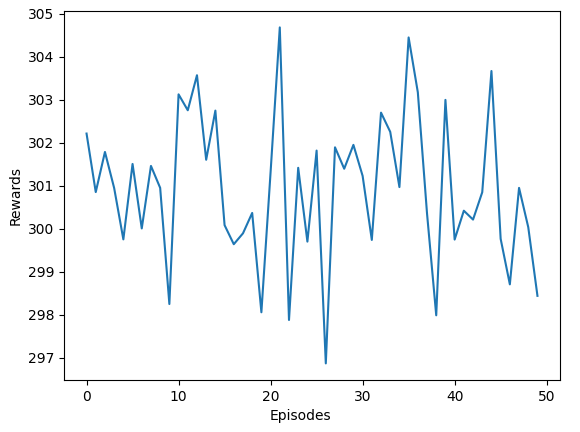
Rewards of fully learned agent in 50 episodes:
How it works
- Generate a randomly weighted neural net
- Create a population of neural nets with mutated weights
- Let every net finish an episode and reward it accordingly
- The better the reward, the higher the chance to pass weights to next gen
Hyperparameters
| Parameter | Description | Interval | Our Choice |
|---|---|---|---|
HIDDEN_LAYER |
Size of hidden layer. | [1;∞[ | 12 |
BIAS |
Add a bias neuron to the input layer. | {0,1} | 0 |
POP_SIZE |
Size of population. | [0;∞[ | 50 |
MUTATION_FACTOR |
Percentage of weights that will be mutated for each mutant. | [0;1] | 0.1 |
LEARNING_RATE |
This is the rate of learning. | [0;1] | 0.03 |
GENS |
Number of generations. | [0;∞[ | 2000 |
MAX_STEPS |
Number of steps that are played in one episode. | [0; 1600] | 300 |
Installation
We use Windows, Anaconda and Python 3.7
conda create -n evo_neuro python=3.7
conda activate evo_neuro
conda install swig
pip install -r requirements.txt
Important Sources
Environment: https://github.com/openai/gym/wiki/BipedalWalker-v2
Table of all Environments: https://github.com/openai/gym/wiki/Table-of-environments
OpenAI Website: https://gym.openai.com/envs/BipedalWalker-v2/
More on evolution strategies: https://openai.com/blog/evolution-strategies/